现在最强的模型 claude-opus-4-7,配上最强的 agent harness claude code,在做投研、研究这类长程复杂任务时依旧难以匹配人类专业研究员。在这篇文章中,我们将梳理清楚现有系统的两个核心问题,并提出一套从“做对”到“做快”的算法路线图。
文中保留了完整的技术细节,同时对关键术语做了通俗解释,文末附有一份「术语速查表」,供非 agent 算法背景的读者查阅。
我们在谈论什么样的“长程任务”
这里说的“长程复杂任务”,指的是那种需要 agent 连续工作很久、调用很多工具、跨越很多步骤才能完成的任务。典型有两类:
- 深度调研一个板块或一家公司——比如一句“帮我调研一下电子布”,背后是几十上百个相关联企业、企业对应的用人群体、企业对应产业链和国家、世界宏观、微观经济的关系、以及无数的研报、财报、电话会纪要的调研、检索、交叉验证和归纳。
- 解决一个需要资深研究员 + 工程师花 1–2 个月才能搞定的算法问题。
理想情况下,你把这种任务交给“最强模型(如 opus 系列)+ 最强 harness(如最新的 Claude Code)+ 某个 slash 指令”,它应该能自己协调一群子 agent 把活干完。但现实是:它经常干不好。问题出在哪?
一、现有系统的两大问题
问题一:Skill 接口写得太“死”,缺协作、缺多源校验,数据不准
很多 skill(agent 可调用的“技能/工具”)的接口写得过于固定——既不能让多个 skill 或 agent 互相协作,也不做多来源的交叉验证。结果就是数据严重不准,而投研里数据一错,投资结论就跟着错。
举两个真实踩过的坑:
- 例子一(估值数据过期):某 skill 输出“机构预测 2026 年归母净利 60 亿元(同比 +83%),对应 PE 约 16x”。问题是——如果真按 60 亿的盈利算,当前股价对应的 PE 早就不是 16x 了。这个 16x 是拿三月份的股价算出来的,数据是旧的。
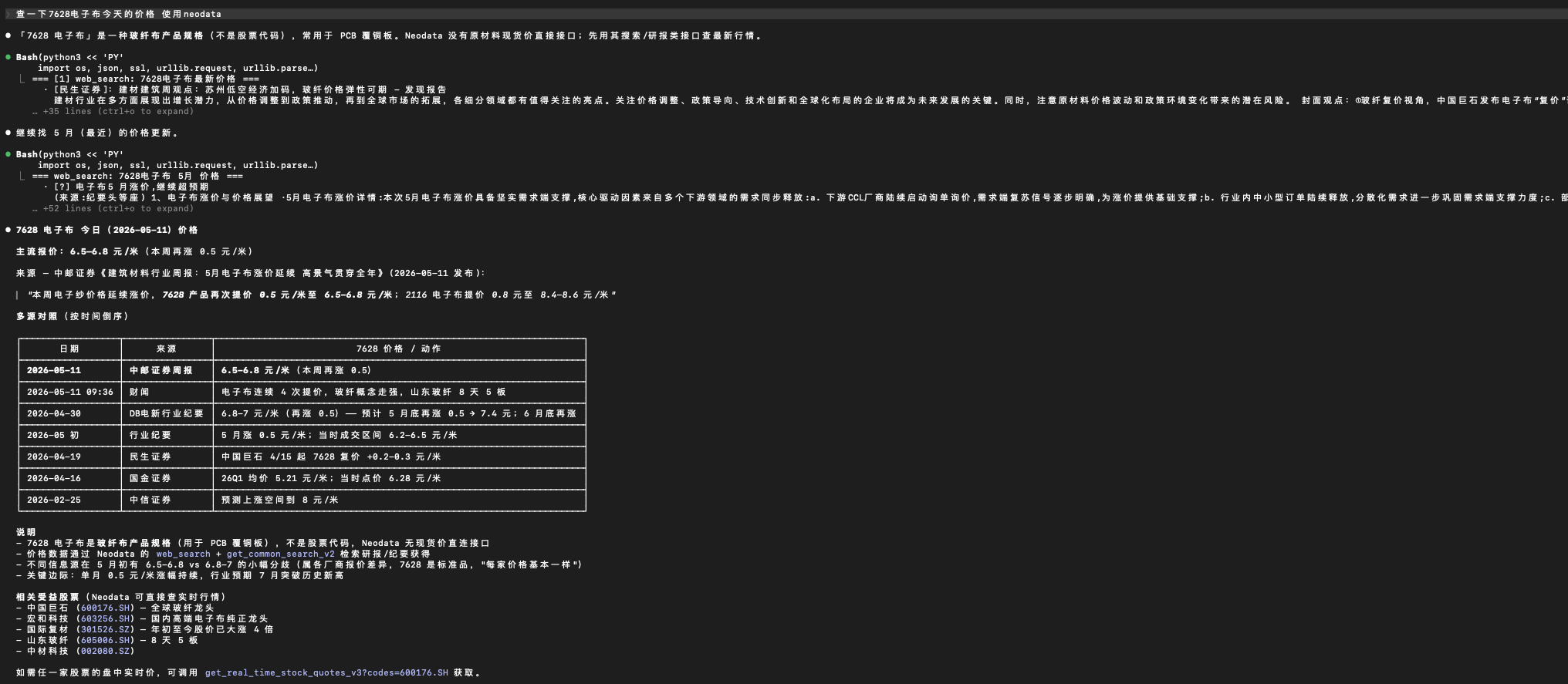
- 例子二(价格数据过期):某 skill 给出“7628 电子布价格从 2025 Q3 末的 4.15 元/米涨到当前约 5.8 元/米,涨幅达 +40%”。可这个所谓“当前价”,其实也是三月份的价格了。
共同的问题:随着上下文的增加,agent 在长程任务中往往在对 skill 返回内容的校验上出现纰漏,经典的表现是利用 skill 接口取到一个数就完事,既不标注时效,也不和其他来源对一对。
解法的雏形已经能看到。 如下图,新开一个 Claude Code 用 neodata 的 skill,就能查询到“电子布”在研报中的最新价格。
问题二:长程任务里 agent 团队会“退化”,且多模态信息处理得很差
这一条其实是两个子问题。
(a) Agent 团队会随着 context 累积而集体“退化”。 任务刚开始时,主 agent 还能正常地协调子 agent / agent team。但随着上下文(context)越积越多——即便你已经做了多层级的 harness 设计(协调者 → 规划者 → 执行者)——后续 subagent / agent team 被调用的频率会越来越低,高层、中层、执行层各级 agent 的完成能力一起下滑。到最后,整个系统像是“急于交差”,任务完成度很低,达不到一开始设定的 goal(完成标准)。
(b) 多模态信息、尤其是音频,处理得既差又不公平。 现有 ASR 模型(把语音转成文字的模型)没法很好地处理多模态信息:对电话会里讲演者的语气、态度、情绪,分析效果很差。更关键的是一种“不公平”——在和同等级信息(财报、机构调研稿)做对比分析时,电话会信息明显没被平等对待:协调 / 规划 agent 倾向于把这类音频信息当成噪音。后果就是,在长程任务中,系统往往第一次调用 ASR 拿到电话会内容之后,就再也不调它了,等于白白丢掉了一类重要信源。
二、算法路线图
针对上面的问题,路线图分成两大块:一块解决“怎么把长程任务做对”(Agent Swarm 的管理方式),另一块解决“怎么把长程任务做快”(长程多轮工具调用的加速)。
(一)Agent Swarm 管理方式:用多层级 harness 啃下长程任务
1. 原子化的多层级 agent 架构
核心思想只有一句:除了一个主 agent,其余所有 agent(协调、规划、执行)全部“原子化”——随时开启、随时关闭,用完即弃,保证每个 agent 的 context 足够干净,从根上对治问题二(a) 里的“上下文越积越退化”。每一种类型、每一组 agent,都能访问 skill / MCP / tools。
各角色的分工是这样的:
- 主 agent:负责和用户讨论、澄清完整的任务,确定任务的完成标准(交付标准);拿到协调 agent 的结果后更新文件 / 文件夹,再传递给下一个协调 agent 组。它同时还是后续的验证器——用一开始和用户敲定的标准,去判定协调 agent 组到底有没有把任务做完。
- 协调 agent 组:讨论并协调主 agent 传来的完整任务和完成标准,把任务拆成探索性的子任务,分配给规划 agent 组。
- 规划 agent 组(+ 探索性规划 skill + skill router):规划“这个任务该怎么探索、怎么完成”,画出一张完整的探索 / 完成路径图,交给执行 agent 组去执行其中确定性的部分;再根据返回结果不断优化路径图 → 派给下一组执行 agent,或把结果交回协调 agent。
- 执行 agent 组(+ 确定性执行 skill + skill router):只干确定性的任务,返回确定性的结果。
一句话把这条流水线串起来:主 agent 对用户负责(定义任务 + 验收),协调 agent 负责拆分探索性任务,规划 agent 负责做探索性规划,执行 agent 负责做确定性执行。 探索(不确定)和执行(确定)被清晰地分到了不同层级。
2. 自进化的 Agent Skill(self-evolved skill)
skill 不该是写死的。思路是:从人工撰写 / “vibe coding” 出来的第一版 skill 出发,结合 agent 的真实执行环境不断迭代,越用越好。
进化有两个方向:
- A. 按数据接口自进化——目标是让取数 / 执行的路径更高效、更准确(正好接住问题一里“接口太死、数据不准”)。
- B. 按用户偏好自进化——目标是让产出的内容在风格、格式上越来越符合用户偏好。
而在“怎么进化”这件事上,又有两种相反的做法:
- 第一种:把单个 skill 做得尽可能详实,覆盖所有情况(大而全)。
- 第二种:把 skill 拆成更细的小 skill,由高层 skill 去调用基础 skill(小而组合)。
那怎么判断 skill 到底有没有往对的方向进化?答案是——用 rubric(评分标准)。
3. 动态 Rubric 模型(dynamic rubric model)
一个任务的完整评分标准,由客观和主观两部分组成:
- A,客观标准:任务本身有的、可量化的完成标准,据此制定客观 rubrics。
- B,主观标准:用户视角的完成标准。做法是模拟不同身份——专业分析师 / 研究员、进阶用户、小白——分别构建各自的主观 rubrics。
把 A + B 合起来,就构成了一道题目的完整评分标准,用它来判定“skill 进化的方向对不对”。之所以叫“动态”,是因为这套 rubric 会随任务和用户身份而变。
4. Skill Router(recall + rerank)
现有的 harness 大多只看 skill 的 name 和 description 来决定调用哪个 skill。可一旦我们拥有大量、而且 name / description 高度重叠的 skill,光看名字和简介就选不准了。
方案是:把“选 skill”这一步从 harness 里解耦出来,在外部单独训练两个约 0.6B 的小模型,组成一个 recall + rerank 的 skill router(先召回候选、再精排)。这两个模型的输入是所有 skill 的 name + description + body(即 skill 的正文 / 实现),做 pointwise / listwise 的排序。
为什么连 body 都要喂进去?报告引用了论文 SkillRouter: Skill Routing for LLM Agents at Scale(arXiv:2603.22455),论证了 skill 的 body 部分对于选对 skill 是必要的。
5. ASR 模型 + HuBERT
针对问题二(b)——电话会音频被当噪音、情绪语气抓不准——路线图给出的方向是引入 ASR 模型 + HuBERT(一种自监督的语音表征模型),来更扎实地处理电话会这类音频 / 多模态信息,让它在与财报、调研稿的对比中得到公平的权重。
(二)长程多轮工具调用的加速
把任务做对之后,还得做快。长程任务动辄几十上百轮工具调用,速度是硬约束。
1. 模型层面的加速
思路是按 agent 的角色分别施策,因为不同角色干的活性质完全不同:
- 执行 agent(确定性任务执行 agent):举个例子,规划 agent 把 3 份 PDF 财报丢给它,让它算某个指标、或判断某个结论能不能成立——这个过程完全可以由一个特定的 skill / SOP(标准作业流程)来控制。这类任务的特点是对准确度要求极高,但高度可程序化。所以加速配方是:程序化合成轨迹(沿用此前的做法 + 特定 skill / 题目)+ 小模型 SFT(4B / A3B 这个量级)+ speculative sampling(投机采样)。
- 规划 agent:用 speculative sampling(mtp / eagle3 / dflash 等方案)。
- 协调 agent:同样用 speculative sampling(mtp / eagle3 / dflash)。
为什么规划和协调这两层要单独对待?因为它们处理的是开放型、探索性、结果不确定性很大的任务,所以底座应该选 glm5.1、dsv4 pro、hy3 preview 这类大型开源 SOTA 模型,然后针对我们自己的任务做加速。加速方案的优先级排序是:
- speculative sampling——在特定任务上加速原模型的推理速度(不改变模型本身的能力);
- 蒸馏(distillation)——采集足够多 SOTA 模型(闭源 / 开源)的轨迹 / logprob,蒸馏(sft / opd / rl)到自己的小模型上。
2. 加速之后的效果评估
加速最怕“快了但变笨了”。所以最后一步,是用前面那套 dynamic rubric model 来评估加速之后的任务完成效果,确保提速没有牺牲质量。评分标准和“判断 skill 进化方向”用的是同一套 rubric 体系,形成闭环。
结语
把这套东西串起来看,逻辑其实很清楚:
- 做对:原子化的多层级 agent(干净 context)+ 自进化 skill(越用越准)+ 动态 rubric(说清什么叫“做好了”)+ skill router(在海量 skill 里选对工具)+ ASR/HuBERT(不再丢掉电话会信息);
- 做快:按角色分层加速——确定性的执行层走“合成轨迹 + 小模型 SFT + 投机采样”,探索性的规划 / 协调层走“大模型底座 + 投机采样 / 蒸馏”;
- 闭环:用同一套动态 rubric,既判断 skill 进化方向,又验收加速后的质量。
最终目标只有一个:让 AI agent 真正胜任投研里那些原本需要专家花 1–2 个月才能搞定的长程复杂任务——数据是新的、信源是全的、过程是快的、结论是对的。
术语速查表
| 术语 | 一句话解释 |
|---|---|
| harness | agent 的“外壳 / 调度框架”,负责管理模型怎么调用工具、怎么协调多个 agent(如 Claude Code)。 |
| skill | agent 可调用的一项“技能 / 工具”,通常包含名称(name)、简介(description)和正文实现(body)。 |
| MCP | 一种让模型统一接入外部工具 / 数据源的协议接口。 |
| subagent / agent team | 主 agent 派生出来、各管一摊的子 agent 或 agent 小组。 |
| context(上下文) | 模型当前“记着”的全部内容;越积越多会拖慢速度、拉低质量。 |
| 原子化 agent | 随开随关、用完即弃的 agent,目的是保持 context 干净。 |
| rubric | 评分量表,把“做得好不好”拆成可打分的标准。 |
| recall + rerank | 信息检索两段式:先“召回”一批候选,再“精排”挑出最优——这里用于选 skill。 |
| ASR | 自动语音识别,把音频(如电话会)转成文字。 |
| HuBERT | 一种自监督学习的语音表征模型,擅长从音频里抽取特征(含语气 / 情绪相关信息)。 |
| SFT | 监督微调,用标注数据进一步训练模型。 |
| distillation(蒸馏) | 让小模型学习大模型的行为 / 输出,从而又小又快又不太掉点。 |
| speculative sampling(投机采样) | 一种推理加速技术:用小模型先“猜”若干 token,再由大模型快速校验,整体出字更快(mtp / eagle3 / dflash 是几种具体方案)。 |
| logprob | 模型对每个候选 token 给出的对数概率,常用于蒸馏 / 分析。 |
| PE | 市盈率,股价 ÷ 每股盈利,估值的常用指标。 |
| 归母净利 | 归属于母公司股东的净利润。 |
| 7628 电子布 | 一种电子级玻璃纤维布的规格型号,PCB / 覆铜板的上游材料。 |
| neodata / opus / glm5.1 / dsv4 pro / hy3 preview 等 | 报告中提到的具体数据接口 / 大模型代号(部分为项目内部或第三方命名)。 |
本文由 claude code opus 4.8 基于 260513 shared report.docx 整理改写而成,保留原报告的全部技术要点,并对术语做了通俗解释。
Today’s strongest model (claude-opus-4-7) paired with the strongest agent harness (claude code) still struggles to match a professional human researcher on long-horizon, complex tasks such as investment research. In this post we lay out the two core problems with current systems, and propose an algorithmic roadmap that goes from “getting it right” to “getting it fast.”
The full technical detail is preserved, while key terms are explained in plain language. A Glossary is included at the end for readers without an agent / ML background.
What Counts as a “Long-Horizon Task”
By “long-horizon, complex task” we mean the kind of task that requires an agent to work continuously for a long time, call many tools, and span many steps before it’s done. Two typical examples:
- Deep-diving a sector or a single company — a one-line request like “research electronic-grade glass cloth for me” sits on top of hundreds of related companies, the workforces behind them, the supply chains and the macro/micro economic links to countries and the wider world, plus countless research notes, financial filings, and earnings-call transcripts to gather, retrieve, cross-validate, and synthesize.
- Solving an algorithm problem that would take an experienced researcher + engineer 1–2 months.
Ideally you’d hand such a task to “the strongest model (e.g. the opus family) + the strongest harness (e.g. the latest Claude Code) + a slash command,” and it would coordinate a swarm of sub-agents to finish the job on its own. In reality, it often does this poorly. Where does it break down?
Part 1 — Two Core Problems with Current Systems
Problem 1: Skill interfaces are too rigid — no collaboration, no multi-source validation, and the data is wrong
Many skills (the “abilities/tools” an agent can call) have interfaces written far too rigidly — they neither let multiple skills or agents collaborate, nor cross-check across multiple sources. The result is badly inaccurate data, and in investment research, wrong data means wrong conclusions.
Two real potholes we’ve hit:
- Example 1 (stale valuation data): A skill outputs “analysts forecast 2026 net profit attributable to the parent of ¥6.0bn (+83% YoY), implying a PE of ~16x.” The problem: if you really run the numbers on ¥6.0bn of earnings, the PE at the current share price is no longer 16x. That 16x was computed off the March share price — the data is stale.
- Example 2 (stale price data): A skill reports “the price of 7628 electronic cloth rose from ¥4.15/m at end-Q3 2025 to about ¥5.8/m currently, up +40%.” But that so-called “current price” is, again, the March price.
The shared root cause: as context grows, the agent in a long-horizon task tends to slip on validating what a skill returns. The classic symptom is grabbing a single number from a skill interface and calling it done — never tagging its as-of date, never reconciling it against another source.
The shape of the fix is already visible. As shown below, spinning up a fresh Claude Code session with the neodata skill retrieves the latest price of “electronic cloth” as quoted in research notes.
Problem 2: In long-horizon tasks the agent team “degrades,” and multimodal information is handled poorly
This one is really two sub-problems.
(a) The agent team collectively “degrades” as context accumulates. At the start of a task, the main agent can still coordinate sub-agents / agent teams normally. But as context piles up — even when you’ve built a multi-level harness (coordinator → planner → executor) — sub-agents / agent teams get called less and less often, and the capability of every layer (high, middle, execution) declines together. By the end the whole system seems to be “rushing to hand something in”: task completion is low and falls short of the goal (the completion bar) set at the outset.
(b) Multimodal information — audio especially — is handled both poorly and unfairly. Current ASR models (which transcribe speech to text) can’t handle multimodal information well: they’re bad at analyzing the tone, attitude, and emotion of a speaker on an earnings call. More importantly there’s an unfairness — when weighed against same-tier information (financial filings, institutional research notes), earnings-call content is clearly not treated as an equal: the coordinator / planner agents tend to treat this audio information as noise. The consequence is that, in a long-horizon task, the system often calls ASR once to get the earnings-call content and then never calls it again — throwing away an important source for free.
Part 2 — The Algorithmic Roadmap
The roadmap splits into two halves: one for “getting the long-horizon task right” (how to manage the agent swarm), and one for “getting it fast” (accelerating long, multi-turn tool calling).
(A) Agent Swarm Management: chewing through long-horizon tasks with a multi-level harness
1. An atomized, multi-level agent architecture
The core idea is one sentence: except for a single main agent, every other agent (coordinator, planner, executor) is “atomized” — spun up and torn down on demand, discarded after use, so that each agent’s context stays clean. This attacks the “context-accumulation degradation” of Problem 2(a) at the root. Every type and every group of agents can access skills / MCP / tools.
The division of labor looks like this:
- Main agent: discusses and clarifies the full task with the user, and fixes the completion bar (delivery criteria); takes the coordinator agents’ results, updates files / folders, and passes them on to the next coordinator group. It also serves as the later verifier — using the criteria agreed with the user up front to judge whether the coordinator group actually finished the task.
- Coordinator agent group: discusses and coordinates the full task and completion bar handed down by the main agent, breaks it into exploratory sub-tasks, and assigns them to the planner agent group.
- Planner agent group (+ exploratory-planning skill + skill router): plans “how to explore and how to finish” this task, draws a complete exploration / completion path map, and hands the deterministic parts to the executor agent group; then, based on what comes back, keeps refining the path map → dispatches the next executor group, or returns results to the coordinator agent.
- Executor agent group (+ deterministic-execution skill + skill router): does only deterministic work and returns deterministic results.
In one line: the main agent answers to the user (define the task + accept the result), the coordinator agent splits exploratory tasks, the planner agent does the exploratory planning, and the executor agent does the deterministic execution. Exploration (uncertain) and execution (certain) are cleanly separated across layers.
2. Self-evolved agent skills
Skills shouldn’t be hard-coded. The idea: start from a first version of a skill written by hand / via “vibe coding,” then iterate it against the agent’s real execution environment so it gets better the more it’s used.
There are two directions of evolution:
- A. Evolve along the data interface — the goal is a more efficient and more accurate retrieval / execution path (which directly addresses the “rigid interface, wrong data” of Problem 1).
- B. Evolve along user preference — the goal is output whose style and format increasingly match what the user wants.
And on how to evolve, there are two opposite approaches:
- Approach 1: make a single skill as exhaustive as possible, covering every case (big-and-complete).
- Approach 2: split a skill into finer sub-skills, with high-level skills calling base skills (small-and-composable).
So how do you judge whether a skill is evolving in the right direction? The answer — a rubric (scoring standard).
3. The dynamic rubric model
A task’s complete scoring standard has an objective and a subjective half:
- A — objective standard: the task’s own quantifiable completion criteria, turned into objective rubrics.
- B — subjective standard: the completion bar from the user’s point of view. The method is to simulate different personas — professional analyst / researcher, power user, novice — and build a subjective rubric for each.
Put A + B together and you get a complete scoring standard for a problem, which you then use to judge “whether the skill is evolving in the right direction.” It’s called dynamic because this rubric shifts with the task and with the persona.
4. Skill Router (recall + rerank)
Most current harnesses decide which skill to call by looking only at the skill’s name and description. But once you have a large number of skills whose names / descriptions heavily overlap, name-and-blurb alone can’t pick the right one.
The solution: decouple “skill selection” out of the harness, and separately train two small models (~0.6B each) into a recall + rerank skill router (recall candidates first, then fine-rank). The input to both models is every skill’s name + description + body (i.e. the skill’s source / implementation), scored pointwise / listwise.
Why feed in the body too? The report cites the paper SkillRouter: Skill Routing for LLM Agents at Scale (arXiv:2603.22455), which argues that the body of a skill is necessary for picking the right skill — name and description aren’t enough.
5. ASR model + HuBERT
For Problem 2(b) — earnings-call audio treated as noise, with tone and emotion missed — the roadmap’s direction is to bring in an ASR model + HuBERT (a self-supervised speech-representation model) to handle earnings-call audio / multimodal information more solidly, so it gets a fair weight alongside filings and research notes.
(B) Accelerating long, multi-turn tool calling
Once the task is done right, it still has to be done fast. A long-horizon task easily runs tens to hundreds of tool calls, and speed is a hard constraint.
1. Model-level acceleration
The idea is to treat each agent role differently, because the work each role does is fundamentally different in nature:
- Executor agent (deterministic-task executor): for example, the planner agent hands it 3 PDF financial filings and asks it to compute some metric, or to judge whether a conclusion holds — a process that can be fully governed by a specific skill / SOP (standard operating procedure). These tasks are extremely accuracy-sensitive but highly programmable. So the acceleration recipe is: programmatically synthesized trajectories (building on prior practice + a specific skill / problem set) + small-model SFT (around 4B / A3B) + speculative sampling.
- Planner agent: speculative sampling (mtp / eagle3 / dflash, etc.).
- Coordinator agent: likewise speculative sampling (mtp / eagle3 / dflash).
Why single out the planner and coordinator layers? Because they handle open-ended, exploratory tasks with large outcome uncertainty, so the base model should be a large open-source SOTA model — glm5.1, dsv4 pro, hy3 preview and the like — which we then accelerate for our own tasks. The priority order of acceleration approaches is:
- speculative sampling — speed up the original model’s inference on a specific task (without changing the model’s own capability);
- distillation — collect enough trajectories / logprobs from SOTA models (closed- or open-source) and distill (sft / opd / rl) them into our own small model.
2. Evaluating completion quality after acceleration
The big risk of acceleration is “faster but dumber.” So the final step is to use the same dynamic rubric model from above to evaluate task-completion quality after acceleration, making sure the speedup didn’t sacrifice quality. Judging “skill-evolution direction” and accepting “post-acceleration quality” use the same rubric system — closing the loop.
Closing
Stringing it all together, the logic is actually clear:
- Get it right: atomized multi-level agents (clean context) + self-evolved skills (more accurate the more they’re used) + dynamic rubrics (spelling out what “done well” means) + a skill router (picking the right tool out of a sea of skills) + ASR/HuBERT (no longer dropping earnings-call information);
- Get it fast: accelerate per role — the deterministic execution layer goes “synthesized trajectories + small-model SFT + speculative sampling,” and the exploratory planning / coordination layer goes “large-model base + speculative sampling / distillation”;
- Close the loop: use one and the same dynamic rubric to both judge skill-evolution direction and accept post-acceleration quality.
There’s only one end goal: to make AI agents genuinely capable of the long-horizon, complex investment-research tasks that used to take an expert 1–2 months — with fresh data, complete sources, a fast process, and correct conclusions.
Glossary
| Term | One-line explanation |
|---|---|
| harness | The agent’s “shell / orchestration framework” — it governs how the model calls tools and coordinates multiple agents (e.g. Claude Code). |
| skill | One “ability / tool” an agent can call; usually has a name, a description, and a body (the implementation). |
| MCP | A protocol/interface that lets a model connect to external tools / data sources in a unified way. |
| subagent / agent team | Child agents or small agent groups spun off by the main agent, each handling its own slice. |
| context | Everything the model is currently “holding”; the more it piles up, the slower and lower-quality it gets. |
| atomized agent | An agent spun up and torn down on demand, discarded after use, to keep context clean. |
| rubric | A scoring rubric that breaks “how well it was done” into scorable criteria. |
| recall + rerank | The two-stage retrieval pattern: first “recall” a candidate set, then “fine-rank” the best — used here to pick a skill. |
| ASR | Automatic Speech Recognition — turning audio (e.g. an earnings call) into text. |
| HuBERT | A self-supervised speech-representation model, good at extracting features from audio (including tone / emotion cues). |
| SFT | Supervised Fine-Tuning — training a model further on labeled data. |
| distillation | Having a small model learn a large model’s behavior / outputs, so it’s small and fast without losing much quality. |
| speculative sampling | An inference-acceleration technique: a small model “guesses” several tokens, a large model quickly verifies them, and overall output is faster (mtp / eagle3 / dflash are specific schemes). |
| logprob | The log-probability a model assigns to each candidate token; often used in distillation / analysis. |
| PE | Price-to-Earnings ratio — share price ÷ earnings per share, a common valuation metric. |
| net profit attributable to parent | Net profit attributable to the shareholders of the parent company. |
| 7628 electronic cloth | A grade of electronic-grade glass-fiber cloth; an upstream material for PCBs / copper-clad laminates. |
| neodata / opus / glm5.1 / dsv4 pro / hy3 preview, etc. | Specific data-interface / large-model codenames mentioned in the report (some are internal or third-party names). |
This post was reorganized and rewritten by claude code opus 4.8 from “260513 shared report.docx,” preserving all technical points of the original report and explaining the terminology in plain language.